Y86
电路逻辑
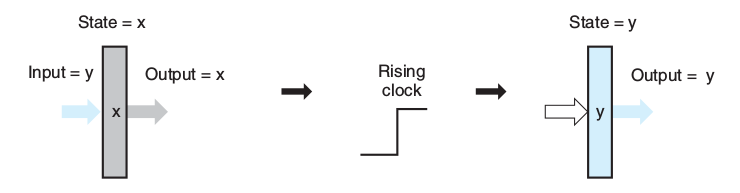
可以把上图长方形看成寄存器的一个单元,Y看成是数据输入,X是输出,时钟信号控制读写。当时钟信号是上升沿时,“写”有效,否则即为“读”
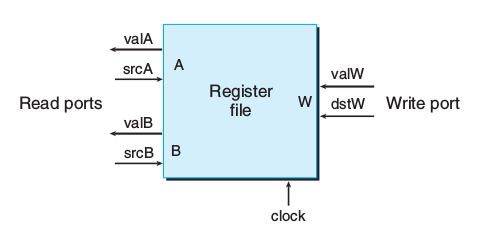
上图为一个寄存器文件,valA和valB相当于X,valW相当于Y,时钟控制读写。
src和dst表示地址,分别决定读和写的目标单元。
显然,读无需Y,写无需X。当对同一单元同时读写时,X是会从旧值变新值。
SEQ
Sequential (顺序执行)
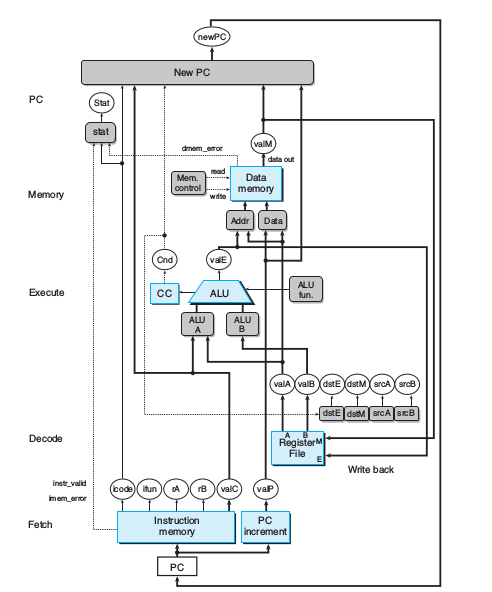
SEQ的实现包括
- 组合逻辑
- 时钟寄存器:PC,CC
- 随机访问存储器:寄存器文件(esp,eax等),指令存储器,数据存储器
加粗表示需要时钟信号,如上面电路逻辑中提到的寄存器文件
下面以push为例说明SEQ

Fetch 指令存储器只读,取指无需一个时钟周期
Decode 译码没涉及到寄存器文件的写,故无需一个时钟周期
Execute 执行减4也无需一个时钟周期,但进行整数运算会涉及CC的写,这需要一个时钟周期。
Memory 访存数据存储器需要一个时钟周期
Write back写回寄存器文件需要一个时钟周期,可与Memory共用一个时钟周期
PC update 更新PC要一个时钟周期
push先算读出esp并计算新值,但未马上更新esp,而是先把写入内存再更新esp(二者可并行)
pop同理。
为什么valE只给address不给data?我觉得地址偏移用的比较多,而把运算结果写入内存用的更少。
而更新后不读,我想是为了指令流水。
取指
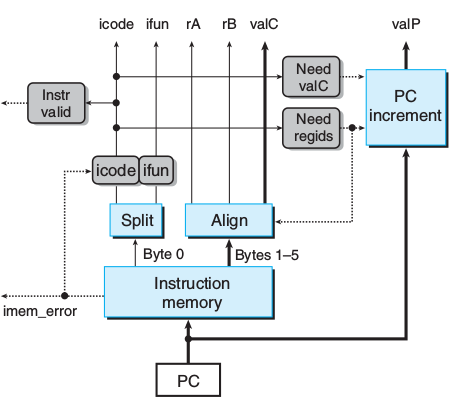
instr_valid = icode in {} #指令合法
need_regids = icode in {} #需要寄存器
need_valC = icode in {} #包含常数
valP是根据need_regids和need_valC来对决定对PC+1,+2,+5,+6
+1 都不要
+2 只需寄存器
+5 只需常数
+6 全要
译码
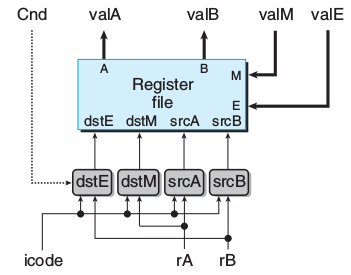
两读两写
int srcA = [
icode in { IRRMOVL, IRMMOVL, IOPL, IPUSHL } : rA;
icode in { IPOPL, IRET } : RESP;
1 : RNONE; # Don’t need register
];
int srcB = [
icode in { IOPL, IRMMOVL, IMRMOVL } : rB;
icode in { IPUSHL, IPOPL, ICALL, IRET } : RESP;
1 : RNONE; # Don’t need register
];
int dstE = [
icode in { IRRMOVL } : rB; #条件转移可根据Cnd决定dstE
icode in { IIRMOVL, IOPL} : rB;
icode in { IPUSHL, IPOPL, ICALL, IRET } : RESP;
1 : RNONE; # Don’t write any register
];
int dstM = [
icode in { IMRMOVL, IPOPL } : rA;
1 : RNONE; # Don’t write any register
];push时要提供address和data,故AB都得用上,
pop是只要address,但为了保持队列,A也给address
E是ALU后write back时的目标,比如esp+4
M是访存后write back时的目标
可以看出寄存器间的mov是通过ALU来来实现的
pop %esp需要E和M,且译码时就定了。因为访存为组合逻辑,不需时钟周期,
故valE和valM可看成同时到位,故M优先级应高于E
执行
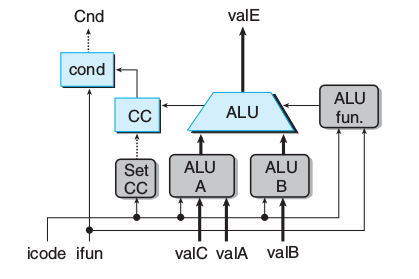
int aluA = [
icode in { IRRMOVL, IOPL } : valA;
icode in { IIRMOVL, IRMMOVL, IMRMOVL } : valC;
icode in { ICALL, IPUSHL } : -4;
icode in { IRET, IPOPL } : 4;
# Other instructions don’t need ALU
];
int aluB = [
icode in { IRMMOVL, IMRMOVL, IOPL, ICALL, IPUSHL, IRET, IPOPL } : valB;
icode in { IRRMOVL, IIRMOVL } : 0;
# Other instructions don’t need ALU
];
int alufun = [
icode == IOPL : ifun;
1 : ALUADD;
];
bool set_cc = icode in { IOPL }; #运算指令要设定CC,跳转指令基于CC访存
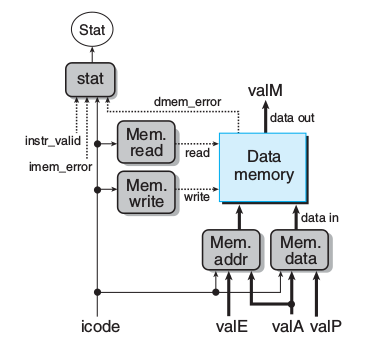
int mem_addr = [
icode in { IRMMOVL, IPUSHL, ICALL, IMRMOVL } : valE;
icode in { IPOPL, IRET } : valA;
# Other instructions don’t need address
];
int mem_data = [
# Value from register
icode in { IRMMOVL, IPUSHL } : valA;
# Return PC
icode == ICALL : valP;
# Default: Don’t write anything
];
bool mem_read = icode in { IMRMOVL, IPOPL, IRET };
bool mem_write = icode in { IRMMOVL, IPUSHL, ICALL };
int Stat = [
imem_error || dmem_error : SADR;
!instr_valid: SINS;
icode == IHALT : SHLT;
1 : SAOK;
];更新PC
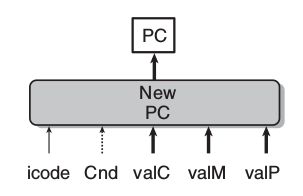
int new_pc = [
# Call. Use instruction constant
icode == ICALL : valC;
# Taken branch. Use instruction constant
icode == IJXX && Cnd : valC;
# Completion of RET instruction. Use value from stack
icode == IRET : valM;
# Default: Use incremented PC
1 : valP;
];常用指令
可以看出rrmovl是opl(rB=0)的特例


下图是上图特例
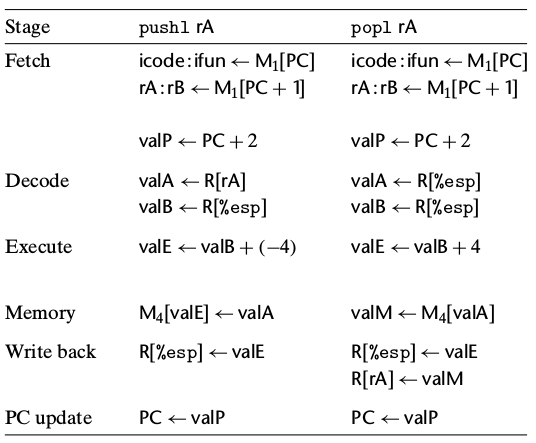

可以看出,数据存储器的地址关联BE组合,读关联M,写关联A
流水线
SEQ+
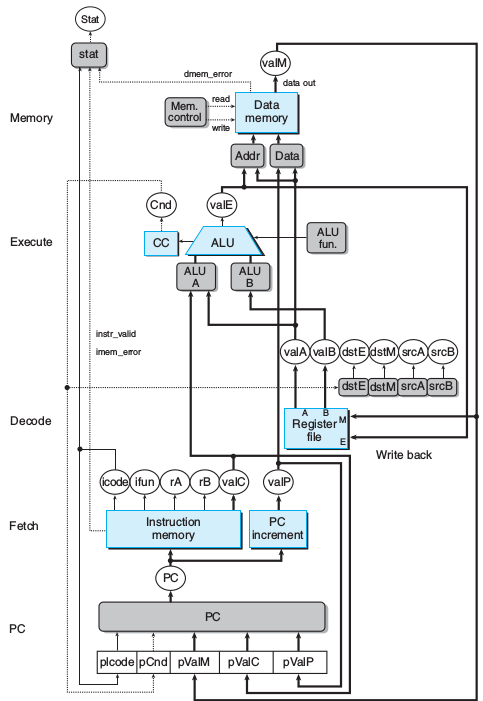
为了实现流水线,将SEQ的更新PC去掉,在取指前根据前一条指令的输出更新PC,逻辑不变。
PIPE
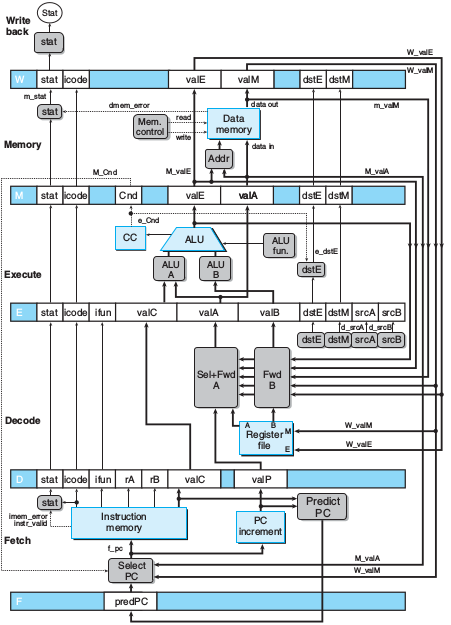
译码时可以通过暂停和转发来解决数据冒险
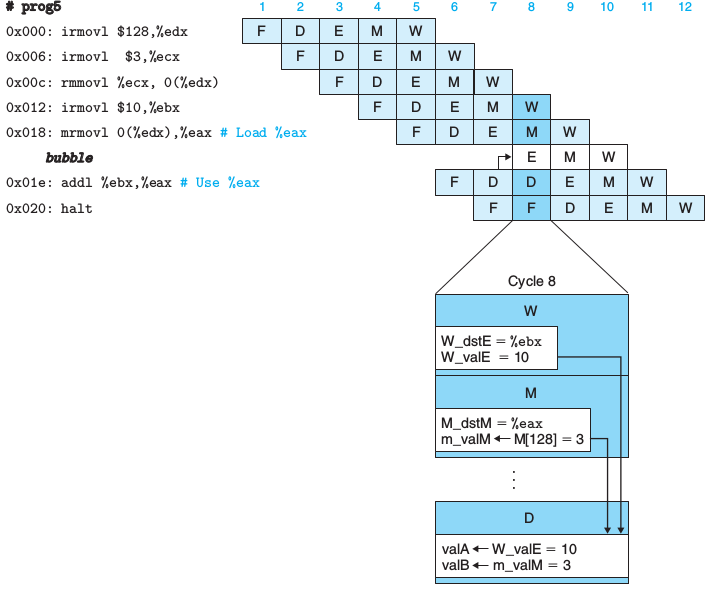
在第7周期,发现第5条指令执行阶段的目的寄存器(%eax)与第6条指令译码阶段的(%eax)冲突,
故在硬件上,第8周期FD保持上一周期状态,E空白,MW照常。
PC选择和取指
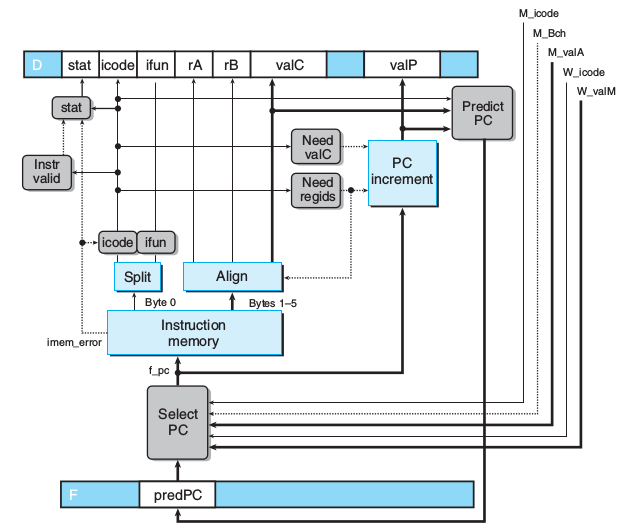
int f_pc = [
# 分支预测错误,本不应该跳。现在继续下条指令。
# M_valA由D_valP传递得,D_valP是JXX下一条地址
M_icode == IJXX && !M_Cnd : M_valA;
# Completion of RET instruction.
W_icode == IRET : W_valM;
# Default: Use predicted value of PC
1 : F_predPC;
];
int f_predPC = [
# ICALL直接跳
# JXX 先直接跳,预测错了再执行JXX下一条指令
f_icode in { IJXX, ICALL } : f_valC;
1 : f_valP;
];
int f_stat = [
imem_error: SADR;
!instr_valid : SINS;
f_icode == IHALT : SHLT;
1 : SAOK;
];如果是JXX先不跳,而是先执行下条,等预测错了再跳,那么代码变动如下
int f_pc = [
# M_valE由E中A+B得到,A是E_valC,B是0,在E,D_valC是JXX跳转地址
M_icode == IJXX && !M_Cnd : M_valE;
W_icode == IRET : W_valM;
1 : F_predPC;
];
int f_predPC = [
f_icode == ICALL : f_valC;
1 : f_valP;
];
#修改E中的aluA和aluB...从PIPE完整图中可以看出传播轨迹
跳转地址 -> D_valC -> E_valC -> M_valE
下条地址 -> D_valP -> E_valA -> M_valA
显然,JXX包含jmp,jmp是无条件直接跳。
如果像课后作业4.54所述,jmp直接跳,其他JXX先执行下条。代码变动如下
int f_pc = [
# Y86中,jmp为70,其他JXX为71,72,73...
M_icode == IJXX && f_ifun != 0 && !M_Cnd : M_valE;
W_icode == IRET : W_valM;
1 : F_predPC;
];
int f_predPC = [
# jmp和call直接跳
f_icode == IJXX && f_ifun == 0 : f_valC;
f_icode == ICALL : f_valC;
1 : f_valP;
];jmp不涉及预测分支错误,因为它不连预测的机会都没有。
应该在流水线控制逻辑中从JXX踢除jmp
即用IJXX && f_ifun != 0 替换 IJXX,像f_pc中那样。需要注意的是e_Cnd是指示的是否满足跳转条件,而非预测的正确性
译码和写回
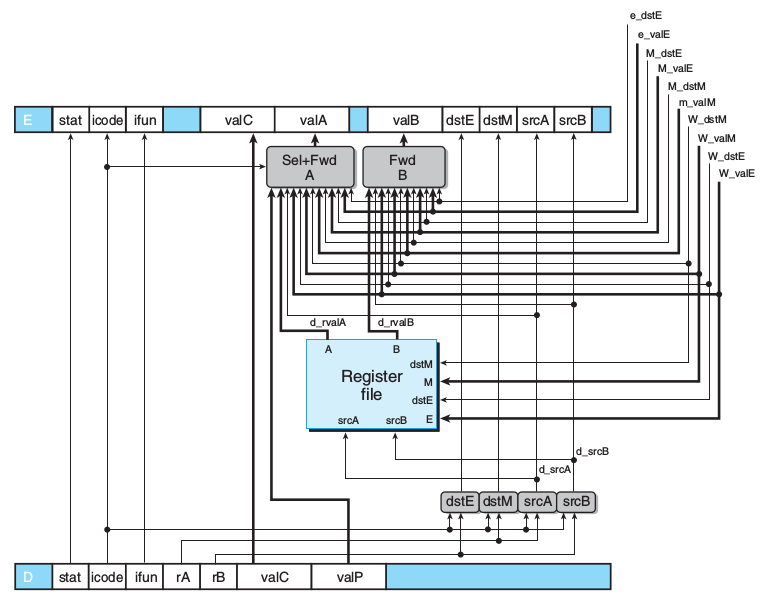
- 在SEQ中,寄存器文件 中的dstE在D时就是等于d_dstE,就是说译码时就知道要写回到哪个寄存器,
而在PIPE中d_dstE是先往上传,传到W时回传寄存器文件dstE,这样dstE只有在W阶段才占有值, W前这段时间可以给其他指令,有利于流水。 - 在下面的代码中从d_valAM取值优先级可以看出M段M_dstM优先级大于M_valE,呼应了前面所说的pop %esp
- 发现在SEQ中D_valP直接给Data,而在PIPE被整合到A中, 因为A和P不会产生冲突。call需要在M时往数据数据俱器中写入P,跳转指令在M时需要回传M_valA,二者都用不到d_valA。
这样D后的流水寄存器就不用给P留位置
int d_valA = [
D_icode in { ICALL, IJXX } : D_valP; # Use incremented PC
d_srcA == e_dstE : e_valE; # Forward valE from execute
d_srcA == M_dstM : m_valM; # Forward valM from memory
d_srcA == M_dstE : M_valE; # Forward valE from memory
d_srcA == W_dstM : W_valM; # Forward valM from write back
d_srcA == W_dstE : W_valE; # Forward valE from write back
1 : d_rvalA; # Use value read from register file
#SEQ中就直接等于d_rvalA
];
int d_valB = [
d_srcB == e_dstE : e_valE;
d_srcB == M_dstM : m_valM;
d_srcB == M_dstE : M_valE;
d_srcB == W_dstM : W_valM;
d_srcB == W_dstE : W_valE;
1 : d_rvalB;
];int d_dstE = [
D_icode in { IRRMOVL } : D_rB;
D_icode in { IIRMOVL, IOPL} : D_rB;
D_icode in { IPUSHL, IPOPL, ICALL, IRET } : RESP;
1 : RNONE; # Don’t write any register
];执行
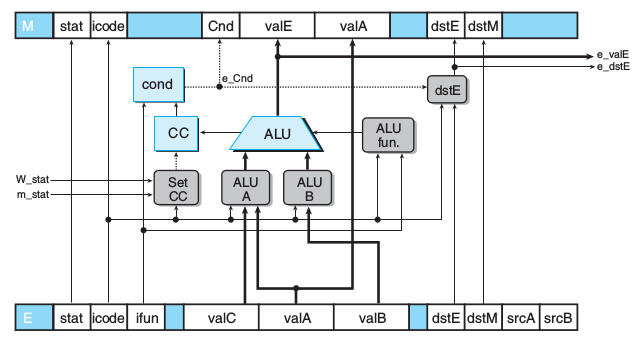
可以看出执行阶段转发给译码阶段的并不是E_dstE,而是e_distE。 因为条件转送要根据e_con和icode来判断是否进行传送
直接转发E_dstE的话,下面结果为0x444
irmovl $0x123,%eax
irmovl $0x321,%edx
xorl %ecx,%ecx # CC = 100
cmovne %eax,%edx # Not transferred
addl %edx,%edx # Should be 0x642
halt访存
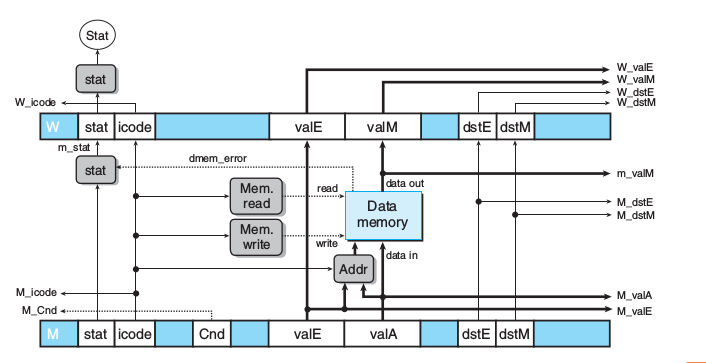
int m_stat = [
dmem_error : SADR;
1 : M_stat;
];写回
int Stat = [
W_stat == SBUB : SAOK; #视暂停为正常状态
1 : W_stat;
];异常
某条指令发生异常后,后面的指令并不会马上停止,只是不能更新CC,受m_stat和W_stat控制。见PIPE的执行阶段图
并且在M阶段插入bubble防止写存,直到异常指令到达最后阶段,
程序停止执行,程序状态为异常指令W寄存器中的stat,后面应该转而执行异常处理程序。
如果指令执行一半发现取错了(分支预测错误),该指令所出现的异常信息会被清空
控制逻辑
RET
执行ret时,后面的指令可以取出,但只取不译,直到访存结束 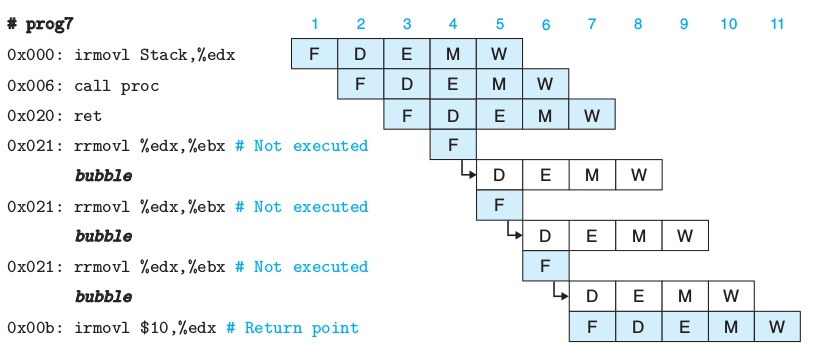
分支预测
执行jXX时,后面的指令可以取出并运行,但在第5周期要视情况是否继续,这由分支逻辑决定是否插入bubble。
若是执行另一分支,转发逻辑会使用PC取M_valA,这在PIPE的译码阶段定义过f_pc。
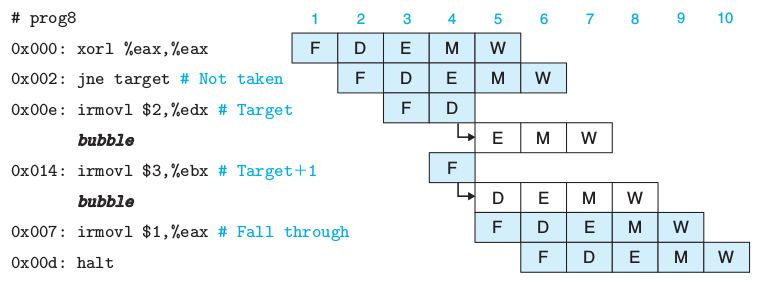
跳转指令可以有不同跳转方式,但大同小异。
加载/使用 冒险
执行pop或mrmov时,会使下条指令暂停一周期,这在PIPE提到过。
总结

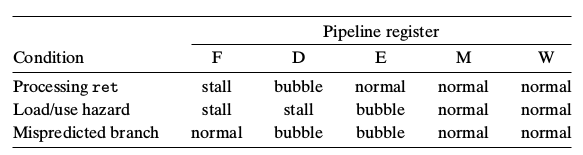
jXX+ret依ret。因为预测正确的话也要依ret规则,不正确的话就随意,反正最后也要换另一分支
pop+ret依pop。因为假如依ret把D给bubble,则ret自己经过D时就会被buble,故推迟1周期等到pop冒险结束
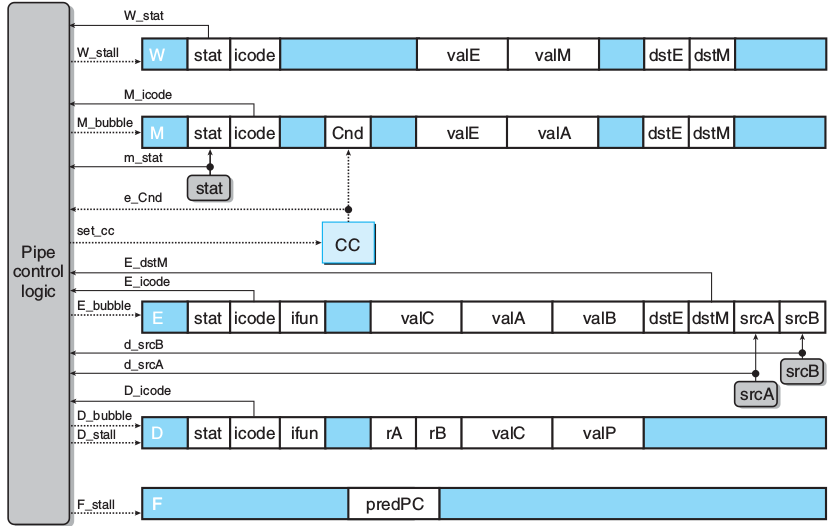
bool F_stall =
#当 加载/使用 冒险
E_icode in { IMRMOVL, IPOPL } &&
E_dstM in { d_srcA, d_srcB } ||
# ret 通过流水线
IRET in { D_icode, E_icode, M_icode };bool D_stall =
# 加载/使用 冒险
E_icode in { IMRMOVL, IPOPL } &&
E_dstM in { d_srcA, d_srcB };
bool D_bubble =
# 预测分支
(E_icode == IJXX && !e_Cnd) ||
# ret
# 且非 加载/使用 冒险
!(E_icode in { IMRMOVL, IPOPL }
&& E_dstM in { d_srcA, d_srcB })
&& IRET in { D_icode, E_icode, M_icode };bool E_bubble =
# 预测分支
(E_icode == IJXX && !e_Cnd) ||
# 加载/使用 冒险
E_icode in { IMRMOVL, IPOPL } &&
E_dstM in { d_srcA, d_srcB};bool set_cc =
E_icode == IOPL &&
#前面指令在M W出错,则后面指令不能改CC,这在[异常]提过
!m_stat in { SADR, SINS, SHLT } && !W_stat in { SADR, SINS, SHLT };
#当前访存异常,则后面访存Bubble
bool M_bubble = m_stat in { SADR, SINS, SHLT } || W_stat in { SADR, SINS, SHLT };
#当前访存异常,则后面写回Bubble,m_stat和W_stat都是指示访存状态
bool W_stall = W_stat in { SADR, SINS, SHLT };